livekit 引入了利用大模型来来做轮次检测,解决AI对话中的误打断,比基于人声的VAD 准确度提高很多,非常有意思的尝试。
技术细节
1、基于 一个 135M的模型(SmolLM2-135M)微调而来,量化之后CPU上就能跑。
2、将意外打断减少了85%,仅有3%的情况下错误地判断对话未结束。
原文: https://blog.livekit.io/using-a-transformer-to-improve-end-of-turn-detection/
目前语音人工智能应用最难解决的问题之一是对话回合结束检测。在对话式人工智能的背景下,轮次判断是确定用户何时结束讲话以及人工智能模型何时可以做出响应而不会无意中打断用户的任务。
检测对话轮次结束的最常见技术称为短语端点。短语端点是一种算法,试图确定用户何时说完完整的想法或话语。几乎每个人,包括 LiveKit 的代理框架,都使用语音活动检测(VAD) 作为短语端点。它的工作原理如下:
- 通过神经网络运行音频数据包,输出音频是否包含人类语音。
- 如果音频样本包含人类语音,则用户尚未说完。
- 如果音频样本不包含人类语音,则启动计时器来跟踪“沉默”的长度(即不存在可检测到的人类语音)。一旦经过了由开发人员您设定的特定时间阈值,而没有人说话,那一刻就代表了话语的结束。人工智能模型现在可以对用户的输入进行推理并做出响应。
代理使用Silero VAD来检测语音活动并提供计时参数来调整其灵敏度。一旦代理确定用户已停止说话,框架就会在启动LLM推理之前引入延迟。
这种延迟有助于区分自然暂停和用户回合结束。您可以使用min_endpointing_delay参数配置此延迟。 min_endpointing_delay的默认值为 500 毫秒。这意味着一旦 VAD 检测到从人类语音到缺失的转变,并且缺失持续至少 500 毫秒,就会触发回合结束事件。
您可以通过降低端点延迟阈值来让代理更快地响应,但代价是频繁中断。如果您将阈值增加到一两秒,您的代理会感觉没有响应。
这里明显的问题是一刀切的方法不可能解释每一种用例、每一种说话风格或每一种口语。
一个更大的问题是,VAD 仅在某人说话时进行识别(通过分析音频信号的存在),而人类还使用语义、某人所说的内容以及他们的说话方式来确定何时轮到他们说话。
例如,如果有人说,“我理解你的观点,但是……”——VAD 会将此称为回合结束,但人类很可能会继续倾听。
几个月来,我们一直在探索如何将语义理解融入 LiveKit Agents 的回合检测系统中。经过大量的实验和测试,我们很高兴发布一个开源 Transformer 模型,该模型使用语音内容来预测用户何时结束讲话。在我们深入研究它的工作原理以及它如何用于轮流检测之前,请先查看结果:https://youtu.be/EYDrSSEP0h0
该模型如何运作
我们的话语结束 (EOU) 模型是一个基于 HuggingFace 的SmolLM v2 的135M 参数转换器,并针对预测用户语音结束的任务进行了微调。考虑到推理需要在 CPU 上实时运行,我们选择了一个小模型。 EOU 在用户和代理之间的对话中使用最后四轮的滑动上下文窗口。
当用户说话时,他们的语音会使用(开发人员指定的)语音到文本 (STT) 服务转录为文本,并且每个单词都会附加到模型的上下文窗口中。
对于从 STT 收到的每个最终转录,该模型都会以置信水平对当前上下文的尾端是否代表当前说话者的回合结束进行预测。
目前,EOU 只能对英语转录进行预测,但我们计划在未来几个月内添加对更多语言的支持。
我们使用模型的方式很简单:模型预测用于动态缩短或延长 VAD 静默超时。这意味着如果 EOU 表明用户尚未说完话,代理将等待更长的沉默时间。
在我们的测试中,我们发现这种策略可以显着减少中断,而不会影响响应能力。与单独使用 VAD 相比,带有 VAD 的 EOU:
- 减少 85% 的无意中断
- 错误地表明转弯次数不超过 3%
它在对话式人工智能和客户支持用例中特别有用,例如进行采访和收集用户的数据(例如地址、电话号码或付款信息)。更多演示:
Ordering a pizza 订购披萨
Providing your address for a shipment 提供您的发货地址
Giving your account number to customer support 将您的帐号提供给客户支持
如何在代理中使用新模型
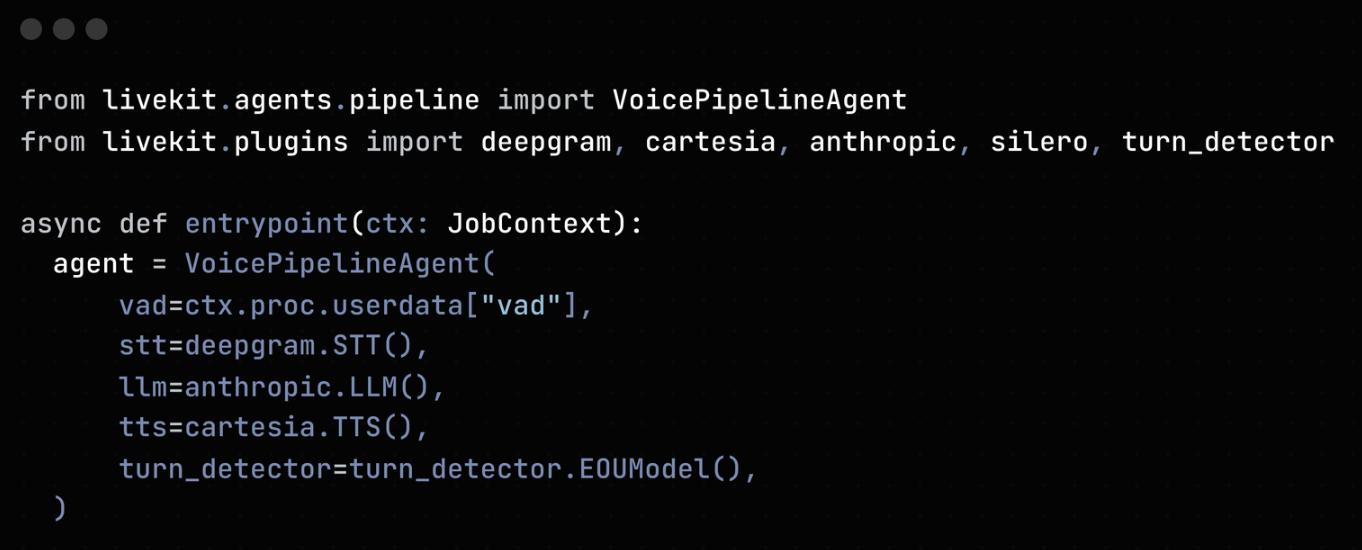
我们将新的转弯检测器打包为 LiveKit Agents 插件,因此可以通过VoicePipelineAgent构造函数中的一个附加 kwarg 将其添加到语音代理中(您可以在此处找到完整的示例代码):
轮次检测的未来
除了扩展 EOU 以支持其他语言之外,我们还希望探索诸如增加上下文窗口和提高模型推理速度(目前约为 50 毫秒)之类的改进。
EOU 在文本上进行训练,因此虽然它在管道架构(即 STT ⇒ LLM ⇒ TTS)中有效(即语音在进一步处理之前转换为文本),但它不能与直接消耗音频输入的本机多模态模型一起使用,例如OpenAI 的模型实时API 。
为了使用多模态模型进行内容感知转弯检测,我们正在研究基于音频的新模型,该模型不仅会考虑说话者所说的内容,还会考虑说话者如何表达自己,使用人类语音中的隐式信息(例如语调和节奏)。
很难描述我们人类用于了解何时轮到我们发言的确切过程,这使得该任务成为基于机器学习的方法的良好候选者。
即使是人类也不能一直正确地做到这一点,非语言提示可以提高我们在这项任务中的表现。我们当面打断别人的次数比在 Zoom 上少,在 Zoom 上打断别人的次数比通过电话少。
我们相信,这一领域的研究对于构建更加人性化、交互感觉自然的人工智能至关重要。我们很高兴通过这个模型为社区做出我们的第一个贡献,并期望随着时间的推移看到这个领域的大量创新。

